
Different Types of RAG in AI
January 15, 2025

Retrieval Augmented Generation (RAG) is a machine learning technique that enhances large language models (LLMs) and helps them perform more accurately. It does so by allowing LLMs to access external information sources to generate more accurate and contextually relevant outputs. These outputs are superior to those that only rely on pre-trained knowledge.
LLMs power services that respond to user inquiries. However, LLMs still struggle with inaccuracies and hallucinations (when the LLM generates a fabricated or nonsensical response). Inaccurate responses and hallucinations are more likely to occur when the LLM is responding to knowledge-intensive questions researching obscure facts or those that demand up-to-date information.
RAG has emerged as a promising solution to some of these issues LLMs face. It uses an external knowledge base to retrieve and incorporate related information into its generated content. Additionally, RAG can reduce factual errors in knowledge-intensive tasks by retrieving more timely and accurate information. While RAG improves response accuracy, longer documents that require complex reasoning can delay LLM response times.
Challenges with Traditional RAG
Despite RAG systems' success, they still face challenges that limit their effectiveness, including:
1. Retrieval Redundancy
Feeding retrieved chunks of data directly into LLMs can overwhelm them with irrelevant or redundant information. This system wastes computational resources and increases the risk of generating an inaccurate response or hallucination. Thus, the challenge is to preserve relevant information while filtering out the noise.
2. Understanding Nuance
Traditional RAG systems struggle with nuance, especially when complex queries are involved.
3. Linear Process Limitations
Traditional RAG systems engage in a linear "retrieve-then-generate" flow, which doesn't always align with complex application needs. Multifaceted queries often require a non-linear approach, and unfortunately, the rigid structure of RAG methods still imposes significant constraints.
RAG technology must evolve to meet the growing complexity of tasks. Furthermore, the need for sophisticated systems that can break free from linear process constraints has led to the development of RAG variations.
These variations include Standard RAG, Corrective RAG, Speculative RAG, Fusion RAG, Agnostic RAG, Self RAG, Graph RAG, and Modular RAG.
Standard RAG
This version of Retrieval Augmented Generation refers to the foundational implementation of RAG. It typically consists of two core components:
1. Retriever
A retriever searches the knowledge base for the most relevant information based on the user's query.
2. Generator
A generator produces a response based on the original prompt and the retrieved information.
Corrective RAG (CRAG)
CRAG is an advanced technique that seeks to improve the accuracy of the generated response by actively evaluating and refining retrieved information before responding. It ensures that the retrieved data is reliable and relevant, reducing the risk of errors or hallucinations.
Speculative RAG
Speculative RAG is a newer framework that achieves state-of-the-art performance in efficiency and accuracy and has two components:
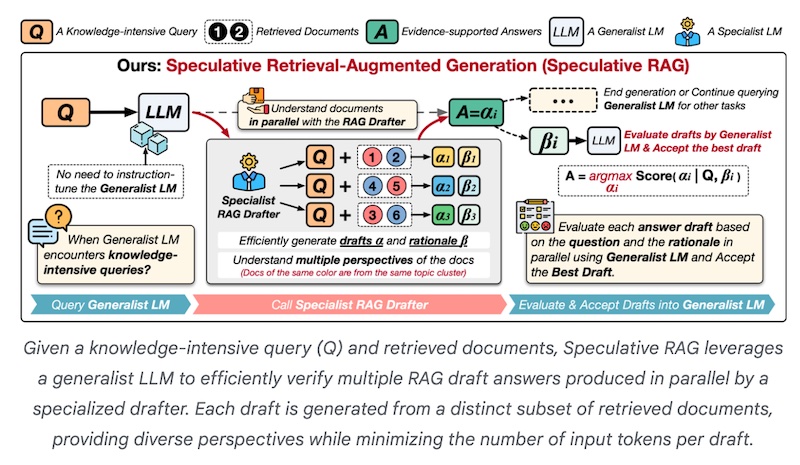
1. Specialist RAG Drafter
This small LM specializes in answering questions but is not expected to cope with general problems. It excels in reasoning over retrieved data and producing rapid responses.
2. Generalist RAG Verifier
The smaller specialist LM above feeds draft texts to this larger generalist LM to select the best draft.
This system operates in the following manner:
(a) The model's retriever obtains related documents from the knowledge base.
(b) It offloads the computational burden to the Specialist RAG drafter.
(c) The Specialist RAG Drafter enables the Generalist RAG Verifier to bypass the detailed review of redundant documents to focus on validating the drafts to find the most accurate answer.
Fusion RAG
This version of RAG combines results from multiple retrieval sources and fuses them together for a more accurate and comprehensive response.
The following are key features of Fusion RAG:
1. Multiple Information Sources
Traditional RAG pulls data from a single source, whereas Fusion RAG retrieves information from various document collections, databases, and knowledge graphs for a broader perspective.
2. Retrieval Fusion
This approach retrieves data from each source and then fuses it to prioritize the most relevant information before bringing it to the language model.
3. Generation Fusion
Another way is to generate multiple response candidates based on multiple retrieved data sets and then fuse them to create a more comprehensive response.
By incorporating data from multiple sources, Fusion RAG can provide more nuanced and accurate answers, especially for complex questions.
Agnostic RAG
This version of Retrieval Augmented Generation refers to a variant where the model is not tied to a specific information source. Thus, it can retrieve relevant data from various sources without requiring pre-defined instructions. This advantage makes it useful in situations with rapidly changing information or unpredictable data needs, such as financial markets.
Key features of Agnostic RAG are flexibility and dynamic retrieval. Unlike standard RAG implementations, which are limited to a specific knowledge base, Agnostic RAG is more flexible and can search across multiple sources based on the query context.
Depending on the query, it can also autonomously decide which data sources to consult. This ability to make autonomous decisions makes Agnostic RAG ideal for situations where the relevant data might be scattered across multiple platforms.
Agnostic RAG is useful when real-time updates are crucial, such as generating market analysis, news summaries, or customer support based on the latest information.
Below is the process:
1. The model analyzes the context of a user's query to identify potential informational sources that might contain relevant data.
2. Next, the model queries multiple data sources to retrieve the most relevant data from each source.
3. The retrieved data is combined with the original query and fed into an LM to generate an accurate response.
SELF RAG
Self-Reflective Retrieval Augmented Generation (SELF RAG) is a framework that enhances traditional RAG capabilities by adding a self-reflection mechanism. SELF RAG allows the AI to critically evaluate its own responses and decide when to retrieve additional data from external sources to improve accuracy.
Key features of SELF RAG:
1. Improved Accuracy
SELF RAG incorporates self-reflection to identify knowledge gaps or inconsistencies in its responses and actively seeks relevant information to provide more accurate answers.
2. Critical Thinking
Standard RAG models basically retrieve and use information, while SELF RAG enables the AI to think critically about the query's context to decide whether additional information is necessary.
3. Enhanced Trust
SELF RAG can build more trust with users by actively seeking out more accurate data.
How SELF RAG operates:
1. The AI generates a response to a user's query based on its internal knowledge. This action is similar to a traditional LLM.
2. The AI goes into self-reflection mode. It analyzes its response to evaluate its confidence level and to identify areas where it might need additional data.
3. If it needs further context, the AI queries a knowledge base to retrieve relevant information.
The retrieved information gets integrated into the initial response to produce a more comprehensive and factually correct answer.
GraphRAG
Most RAG systems use vector similarity (a technique that compares vectors to find similar data points) as the search technique. GraphRAG uses LLM-generated knowledge graphs to provide extensive improvements in question-and-answer performance when conducting complex analysis.
GraphRAG significantly improves the retrieval process of RAG by using an LLM-generated knowledge graph. It populates the context window with more relevant content, which results in better answers.
Users must be able to trust and verify that LLM-generated results are factually correct and accurately represent content found in the source material.
GraphRAG provides the source from the dataset, as it generates each response. Having the cited source readily available enables users to quickly audit the LLM's output against the original source.
The LLM processes the entire dataset and creates references to all the entities and their relationships within the source data. It uses the data to develop an LLM-generated knowledge graph. This graph then organizes the data into semantic clusters, allowing for pre-summarization of semantic concepts, which aids in the LLM's holistic understanding of the dataset.
When a user queries, it uses these structures to provide materials for the LLM context window to answer their question. The context window is the amount of text, in tokens, that the model can remember at any one time. Larger context windows typically mean higher costs per user query.
Modular RAG
Traditional RAG systems that employ a rigid "retrieve-then-generate" process struggle with diverse data sources and complex queries. Modular RAG improves this process with a more flexible system. In the same way that LEGO block structures have smaller pieces combined to make up the whole, Modular RAG breaks down RAG systems into reconfigurable modules, offering the adaptability today's LLMs need.
Understanding the nuances of these different RAG types is vital for AI practitioners and researchers.
